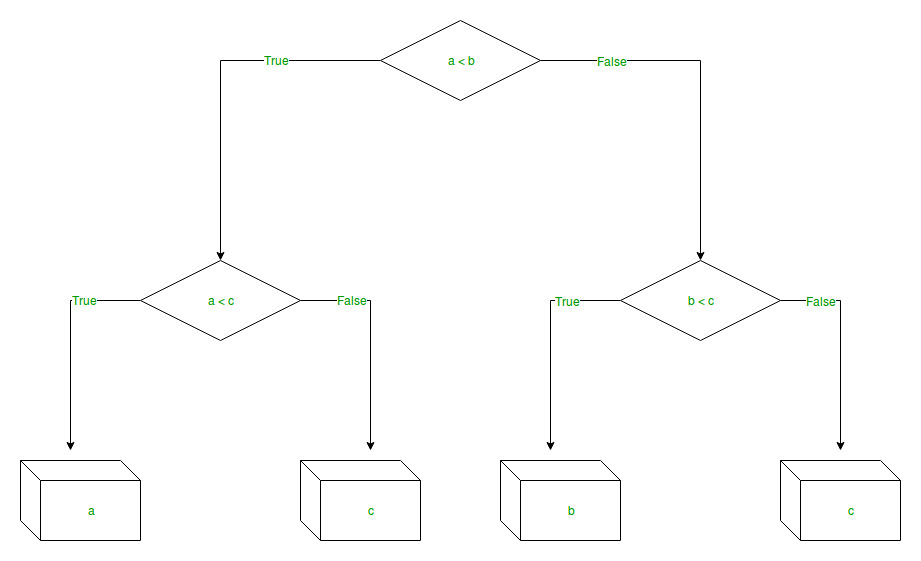
Training and deploying machine learning models using Python
These steps are:
- Specify Performance Requirements.
- Separate Prediction Algorithm From Model Coefficients.
- Develop Regression Tests For Your Model.
- Develop Back-Testing and Now-Testing Infrastructure.
- Challenge Then Trial Model Updates.
Getting a dataset
Machine learning projects are finding good datasets. If the dataset is bad, or too small, we cannot make accurate predictions. You can find some good datasets at Kaggle.
Features are independent variables which affect the dependent variable called the label.
In this case, we have one label column wine quality that is affected by all the other columns (features like pH, density, acidity, and so on).
I use a library called pandas to control my dataset. pandas provides datasets with many functions to select and manipulate data.
First, I load the dataset to a panda and split it into the label and its features. I then grab the label column by its name (quality) and then drop the column to get all the features.
import pandas as pd
#loading our data as a panda
df = pd.read_csv('winequality-red.csv', delimiter=";")
#getting only the column called quality
label = df['quality']
#getting every column except for quality
features = df.drop('quality', axis=1)
Training a model
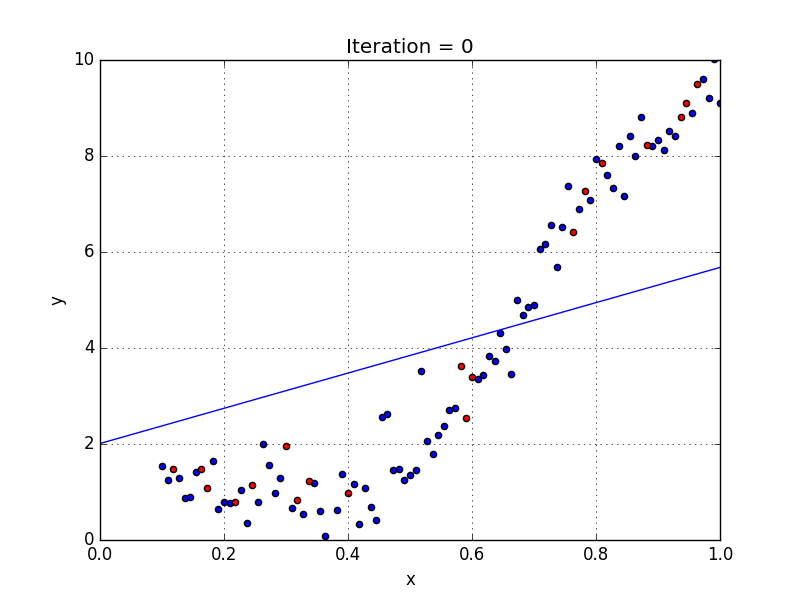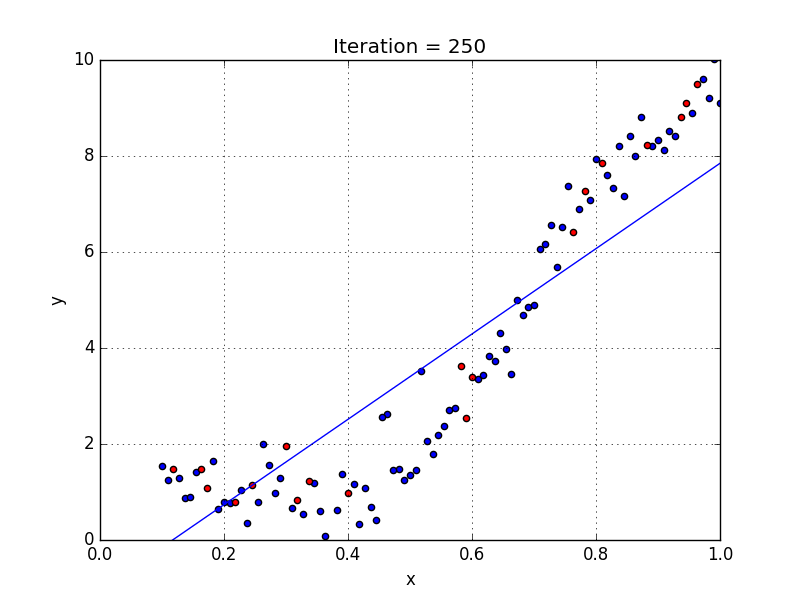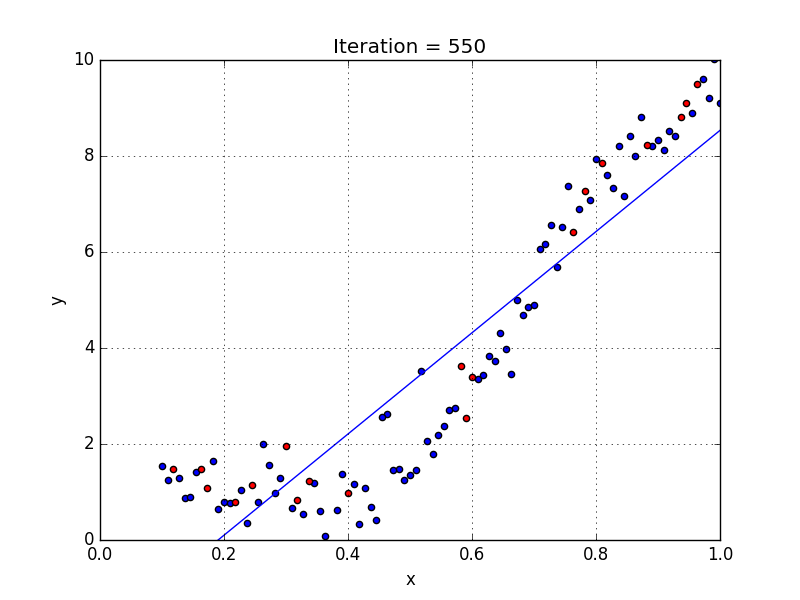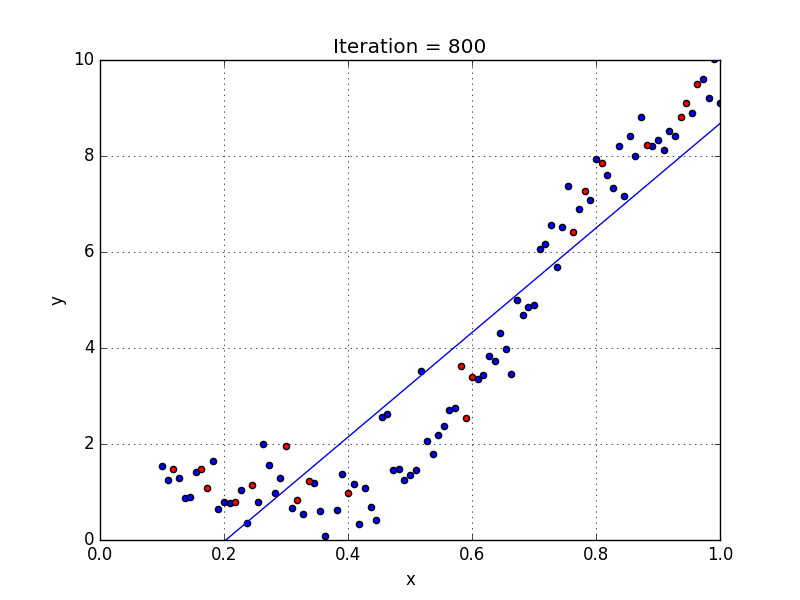
Machine learning works by finding a relationship between a label and its features. We do this by showing an object (our model) a bunch of examples from our dataset. Each example helps define how each feature affects the label. We refer to this process as training our model.
I use the estimator object from the Scikit-learn library for simple machine learning. Estimators are empty models that create relationships through a predefined algorithm.
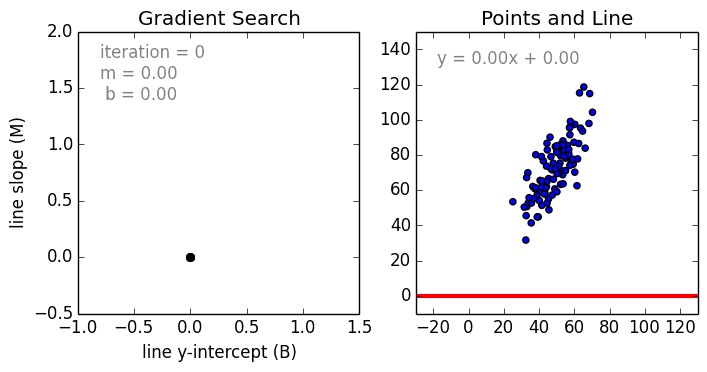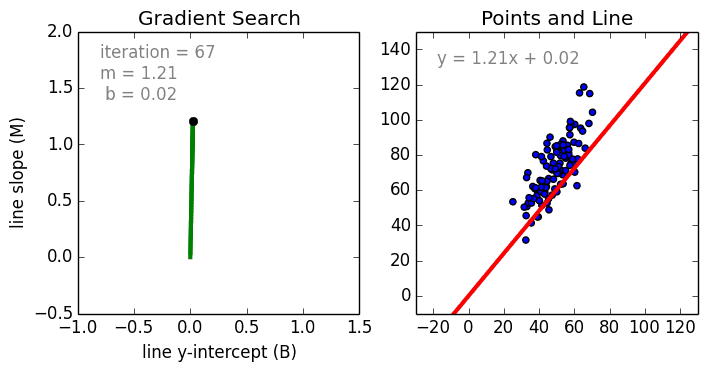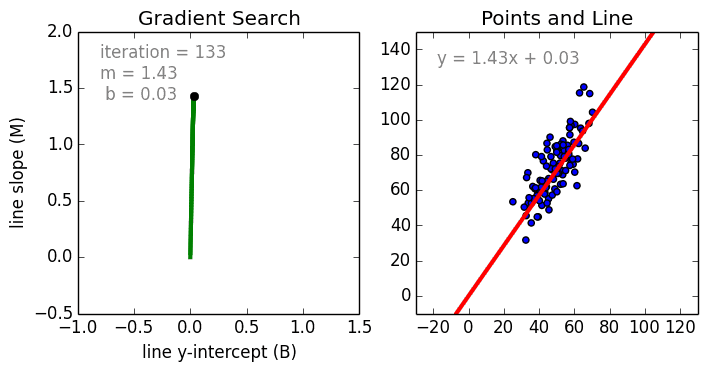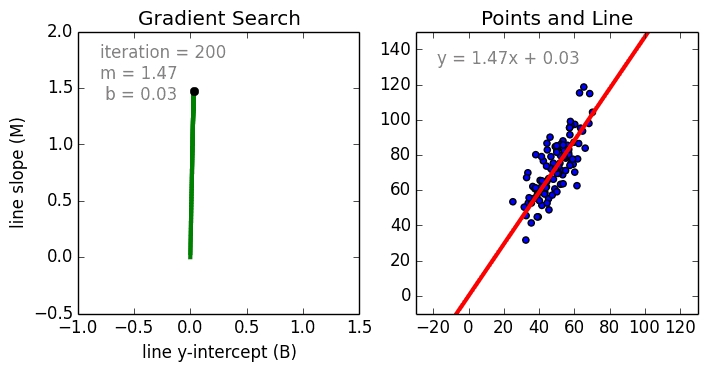
For this wine dataset, I create a model from a linear regression estimator. (Linear regression attempts to draw a straight line of best fit through our dataset.) The model is able to get the regression data through the fit function. I can use the model by passing in a fake set of features through the predict function. The example below shows the features for one fake wine. The model will output an answer based on its training.
The code for this model, and fake wine, is below:
import pandas as pd
import numpy as np
from sklearn import linear_model
#loading and separating our wine dataset into labels and features
df = pd.read_csv('winequality-red.csv', delimiter=";")
label = df['quality']
features = df.drop('quality', axis=1)
#defining our linear regression estimator and training it with our wine data
regr = linear_model.LinearRegression()
regr.fit(features, label)
#using our trained model to predict a fake wine
#each number represents a feature like pH, acidity, etc.
print regr.predict([[7.4,0.66,0,1.8,0.075,13,40,0.9978,3.51,0.56,9.4]]).tolist()
Importing and exporting our Python model
The pickle library makes it easy to serialize the models into files that I create. I am also able to load the model back into my code. This allows me to keep my model training code separated from the code that deploys my model.
I can import or export my Python model for use in other Python scripts with the code below:
import pickle
#creating and training a model
regr = linear_model.LinearRegression()
regr.fit(features, label)
#serializing our model to a file called model.pkl
pickle.dump(regr, open("model.pkl","wb"))
#loading a model from a file called model.pkl
model = pickle.load(open("model.pkl","r"))